03 Apr 2011
Salah satu keuntungan menggunakan version control adalah dia akan menyimpan semua history perubahan. Dengan demikian, walaupun kita sudah menghapus satu file tertentu, sebetulnya file tersebut masih ada di repository dan bisa dimunculkan kembali kapan saja.
Hal ini menimbulkan beberapa konsekuensi, diantaranya
-
Ukuran repository menjadi besar. Ini terutama sangat terasa di Git, karena pada waktu clone, kita akan mengambil keseluruhan perubahan dari pertama hingga terakhir. Berbeda dengan Subversion, dimana kita hanya mendapat perubahan terakhir saja.
-
File-file yang mengandung informasi rahasia –seperti misalnya password– tidak terhapus secara sempurna, sehingga bisa disalahgunakan orang lain.
Untuk itu, kita perlu cara untuk menghilangkan file ini secara permanen.
Di Git, caranya adalah menggunakan perintah git filter-branch seperti dijelaskan di sini. Walaupun demikian, tutorial tersebut tidak menjelaskan bagaimana cara menghapus folder.
Di ArtiVisi, Dadang dan Doni mengalami kejadian tersebut, dimana folder konfigurasi Eclipse (.project, .classpath, .settings) dan file hasil kompilasi Maven (target) ikut serta dicommit. Ini menyulitkan fakir bandwidth yang ingin melakukan clone, karena ukuran reponya menjadi besar sekali. Karena itu, file dan folder tersebut harus dihapus secara permanen.
Cara menghapusnya adalah sebagai berikut.
Pastikan versi repository di local dan di remote sudah sama
Ini bisa dilakukan dengan menggunakan perintah git pull dan git push. Selanjutnya, kita masuk ke folder kerja, dan memanggil perintah berikut.
Perintah di atas akan memodifikasi seluruh commit untuk menghilangkan file dan folder tersebut. Konsekuensinya, seluruh downline Anda akan terpaksa melakukan clone ulang, karena ini sama saja mengganti repository tersebut dengan repository baru. Akibatnya, commit, push, pull, dan merge tidak akan berjalan dengan baik.
Periksa kembali repository Git Anda setelah melakukan perintah di atas, pastikan semuanya baik-baik saja.
Begitu yakin, kita push ke remote.
`
git push origin master –force
`
Setelah melakukan perintah di atas, file yang terhapus itu masih ada di object database Git kita di local, sehingga ukuran reponya masih belum berkurang secara signifikan.
Karena sudah kita push ke remote, hapus saja repo local yang sekarang, dan lakukan clone ulang dari remote.
Demikian cara membersihkan repository dari file yang tidak sengaja dicommit. Silahkan mencoba.
14 Feb 2011
Artikel ini saya tulis berdasarkan diskusi tentang transaction di milis id-mysql. Awalnya sederhana, ada yang tanya begini,
halo rekan2 dba & developer
mysql-innodb kan punya fasilitas transaction yang seperti oracle/postgres tuh.
mau nanya, dalam implementasi real di aplikasi,
contoh bussiness process/use case apa aja yang menggunakan transaction?
kemudian contoh kasus rollbacknya gimana?
Tadinya saya kurang semangat menjawab, karena asumsi saya, ini pertanyaan mendasar, dan pastilah banyak yang bisa menjawab secara benar dan tidak menyesatkan. Tapi apa lacur, saya membaca pertanyaan lanjutan seperti ini.
Ada yang pernah punya pengalaman pake software accounting tanpa feature
transaction?
Dan jawabannya ternyata sangat mengerikan.
yup, pernah.. 3 aplikasi sudah berjalan berbeda2 kasus accounting nya..
dan tidak menggunakan feature transaction…
skrng sedang garap accounting lainnya untuk perusahan dagang, dan
sudah direncakan tanpa feature transaction.
yg aplikasi 1 dr taun 2002, aplikasi 2 dr taun 2004, aplikasi 3 dr jan 2010.
oya, ada jg aplikasi lain di sekitar taun 2005-2009, beberapa masih
dipakai, beberapa tdk dipakai karena masalah internal mereka.
dan selama ini aplikasi yg telah dipakai masih ok2 saja pak.
menurut singkat saya, jika peng-handle php nya sudah cukup
menanggulangi masalah transaksi data, tidak harus menggunakan feature
transaction pada database nya.
karena pd umumnya yg sudah berjalan, kebutuhan inti ada pada
pencarian, input, edit, delete dengan kecepatan yg tinggi dan diakses
oleh beberapa user, dan juga optimize database, dengan begitu menurut
hemat saya, saya lebih condong menggunakan MyIsam yg tdk menggunakan
feature transaction yg sedikit memberatkan proses data.
oya, untuk case mengharuskan memakai feature transaction itu misalnya
pada kasus:
jika pada aplikasi tidak meng-handle apabila ada data transaksi yg
dihapus/update/input yg mengharuskan ada link data yg juga ikut
terupdate/terhapus/terinput
untuk yg sudah menggunakan feature transaction, silahkan saya juga
menunggu tanggapan dan pengalamannya.
What the @#$!
Ini kalo meminjam istilah MUI, harus dibimbing untuk kembali ke jalan yang benar, tapi tidak boleh anarkis :D
Salah satu poin penting dalam database transaction adalah atomic, yaitu beberapa perintah dianggap sebagai satu kesatuan.
Kalau satu gagal, yang lain harus dibatalkan.
Ini adalah fundamental dari pemrograman dengan menggunakan database relasional.
Pada kasus apa perlu transaction?
Ya pada semua kasus yang perlu atomic.
Contohnya : header detail. Sekali insert, 1 header dan beberapa detail.
Kalo pada waktu insert detail gagal, ya headernya harus diundo, kalo ngga ada header yang gantung tanpa detail sehingga datanya juga jadi salah.
Sekarang balik saya tanya, aplikasi apa yang gak pake skema header detail?
Kecuali aplikasi prakarya tugas sekolah, aplikasi bisnis pasti pake header detail.
Itu masalah atomicity. Kemudian ada masalah isolation.
Isolation ini artinya, transaction yang belum dicommit, tidak akan bisa dibaca oleh session lain.
Contohnya gini, kita terima order 1000 item.
Tentunya butuh waktu untuk menginsert 1000 record, misalnya butuh waktu 2 detik.
Di dunia prosesor, 2 detik itu lama sekali, dan banyak hal bisa terjadi dalam rentang waktu tersebut.
Nah, akan terjadi musibah, kalo kita ternyata ada fitur untuk menghitung jumlah order, katakan saja querynya seperti ini.
select sum(nilai) from t_order where tanggal = '2011-02-02'
yang berjalan di tengah-tengah proses insert tadi, misalnya pada waktu baru terinsert 53 order saja. Query hitung ini dijalankan oleh user lain. Suatu hal yang sangat umum terjadi, aplikasi diakses beberapa user berbarengan.
Query ini akan menghasilkan nilai yang salah, karena 1000 order itu belum tentu sukses diinsert.
Misalnya pada record ke 143 terjadi mati lampu, hardisk penuh, komputer hang, browser ketutup, laptop kesiram kopi, usernya menekan tombol cancel, validasi stok produk tidak cukup, atau whatever kejadian remeh-temeh yang umum terjadi dalam kehidupan sehari-hari, tentu akan terjadi kekacauan.
Karena tidak atomic, maka kita tidak tau sudah berapa record yang terinsert, sehingga menyulitkan proses recovery. Order mana yang harus diinsert ulang, dan order mana yang sudah masuk?
Karena tidak ada isolation, maka user yang menjalankan perhitungan order akan mendapat hasil yang tidak sahih kebenarannya.
Seandainya saja kita menggunakan transaction dengan benar, maka pada waktu terjadi sesuatu pada waktu proses insert tadi, maka posisi database akan dikembalikan ke posisi sebelum insert dilakukan. Karena posisi sebelum insert kita tahu dengan pasti, maka recovery gampang.
Insert ulang saja 1000 order tadi tanpa kecuali. Sederhana dan mudah.
Jadi kalo ada di sini yang bilang bikin aplikasi bisnis tanpa transaction, maka itu adalah nonsense.
Tidak peduli kalo sampe saat ini jalan lancar, maka itu hanyalah kebetulan belaka, dan kita tidak mau selamanya mengandalkan keberuntungan kan?
Kalau sampai saat ini berjalan lancar, ya mungkin aplikasinya cuma dipakai 1 concurrent user saja dan itupun jarang-jarang pake.
Nah, jadi transaction itu adalah fitur fundamental yang harus digunakan, sama seperti kalo kita keluar rumah ya harus pake celana.
Di daerah lain sana orang kemana2 cuma pake koteka, dan saya tidak mau berdebat dengan mereka urusan celana.
Jadi kalo masih ada yang bersikukuh bikin aplikasi bisnis gak pake transaction, ya silahkan, saya tidak mau berdebat urusan ini.
Percuma berdebat sama orang yang gak pake celana ;p
Selanjutnya, sebetulnya apa benar transaction itu memberatkan aplikasi?
Hmm … ini sebetulnya hanyalah mitos belaka.
Yang mau mendebat silahkan sajikan benchmark antara non-transactional dan transactional.
Kalo selisih performance cuma 100%, artinya kalo non-transactional cuma 2 kali lebih lemot, saya mendingan upgrade hardware daripada mengorbankan data integrity untuk gain performance yang tidak seberapa ini.
Jadi, apa kita tidak boleh pakai MyISAM ?
Tentu ada waktu dan tempatnya.
Data2 read only seperti misalnya tabel kategori, master produk, bolehlah pake MyISAM.
Tapi kalo sudah data header detail, ya harus InnoDB dan harus menggunakan transaction supaya atomic.
Setelah kita menggunakan InnoDB, sebetulnya kita tidak bisa non-transactional.
Kalo kita tidak begin dan commit secara explisit, sebenarnya untuk tiap SQL statement, itu dianggap satu transaction.
Sehingga SQL seperti ini :
update table harga set nilai = nilai + 1000;
Sebetulnya akan dijalankan seperti ini ;
begin;
update table harga set nilai = nilai + 1000;
commit;
Ini namanya fitur autocommit. Di MySQL defaultnya dienable.
Dengan adanya autocommit ini, justru kita akan lebih lemot kalo tidak menggunakan transaction secara benar.
Contoh, insert 100 data produk.
Kalo tanpa begin dan commit explisit, berarti ada 100 begin dan ada 100 commit, artinya 100 kali menjalankan transaction.
Akan lebih efisien kalo kita lakukan explisit, seperti ini :
begin;
insert into table produk (kode) values ('P-001');
... ulangi 99 kali lagi ..
commit;
Cara di atas hanya akan membutuhkan satu transaction saja.
Jauh lebih efisien.
Baiklah, ada beberapa pesan moral di artikel ini
-
Header detail harus dioperasikan secara atomic
-
Operasi yang belum selesai, tidak boleh dilihat session lain, sehingga untuk aplikasi multiuser, pasti butuh isolation
-
Karena aplikasi bisnis umumnya multiuser, dan pasti punya skema header-detail, maka pasti harusmenggunakan transaction
-
Masalah performance di transaction umumnya mitos belaka, dan walaupun ada, tidak sebanding dengan mengabaikan integritas data
-
Jangan lupa pakai celana kalau keluar rumah
Pembaca setia blog saya tentu paham bahwa biasanya saya memberikan anjuran dengan kata-kata sebaiknya, tergantung situasi, dan istilah-istilah yang relatif. Tapi di artikel ini, banyak kata-kata pasti, harus, dan sejenisnya. Ini karena masalah transaction ini berkaitan dengan integritas data. Aplikasi yang kita buat haruslah bisa dipercaya untuk menghasilkan perhitungan yang benar. Tanpa menjaga integritas data dengan transaction, mustahil perhitungan yang benar bisa didapatkan.
Lebih lanjut tentang masalah-masalah yang bisa terjadi, bisa lihat di Wikipedia.
08 Feb 2011
Pada artikel ini, kita akan mengulas secara singkat perintah-perintah yang sering kita gunakan dalam Git. Tapi sebelum mulai, perlu kita pahami beberapa istilah sebagai berikut:
-
diff : perbedaan antara satu file dengan file lain
biasanya diff dilakukan terhadap satu file yang sudah berubah isinya
-
changeset : kumpulan diff
-
working folder : folder kerja kita, berisi file yang (mungkin) sudah berubah sejak commit terakhir
-
staging : tempat persiapan changeset yang akan dicommit
-
commit : snapshot dari posisi folder dan file pada waktu tertentu
-
tip : commit paling ujung
-
head : nama lain tip
-
branch : head yang diberi nama
-
HEAD : head yang sedang aktif
-
merge : menggabungkan lebih dari satu commit
Membuat Repository
Untuk bisa mulai bekerja, kita harus memiliki repository dulu. Ada dua kemungkinan, kita membuat repository baru, atau kita membuat clone dari repository yang sudah ada.
| Keterangan |
Perintah |
| membuat repository baru |
git init |
| membuat repository baru di folder project-baru |
git init project-baru |
| membuat repository untuk dishare |
git init –bare project-baru |
| copy repository lain |
git clone repo-url |
pilihan format URL
file:///path/ke/repo : clone dari folder lokal
/path/ke/repo : clone dari folder lokal, menggunakan hard link
http://server/path/ke/repo : clone melalui protokol http
username@server:path/ke/repo : clone melalui protokol ssh
Bekerja dengan Git
Berikut ini adalah perintah yang dilakukan selama sesi coding.
Keterangan | Perintah
————————————————————————————————————————|—————————————–
Menambah file baru | git add namafile
Menghapus file | git rm namafile
Memasukkan perubahan di satu file ke staging area | git add namafile
memasukkan semua perubahan | git add .
memilih potongan kode yang akan dimasukkan | git add -p
memasukkan perubahan ke staging menggunakan menu | git add -i
melihat status perubahan file, mana yang masih di working dan mana yang sudah di staging | git status
mengeluarkan perubahan dari staging area | git reset – namafile
melihat perubahan yang belum dimasukkan ke staging area | git diff
melihat perubahan yang akan dicommit (sudah ada di staging area) | git diff –staged
melihat perubahan antara working folder dan commit terakhir | git diff HEAD
melihat file mana saja yang berubah | git diff –name-status abc123..def456
melakukan commit, editor akan diaktifkan untuk mengisi keterangan | git commit
melakukan commit, langsung mengisi keterangan | git commit -m “langsung isi keterangan di sini”
commit langsung semua perubahan, tanpa melalui staging | git commit -a
melihat commit history | git log
log lima commit terakhir | git log -5
log hanya menampilkan summary | git log –oneline
tampilkan commit summary dari semua branch dengan graph hubungan antar commit | git log –oneline –all –graph
membuat commit baru yang berkebalikan dengan (undo) commit terakhir | git revert HEAD
undo 2 commit terakhir | git revert HEAD~2
memindahkan HEAD ke commit-id yang diminta, staging disamakan dengan HEAD, working tetap seperti semula.
Ini adalah opsi defaultnya reset | git reset –mixed
memindahkan HEAD ke commit-id yang diminta, isi working dan staging disamakan dengan commit-id tersebut | git reset –hard commit-id
memindahkan HEAD ke commit-id yang diminta, staging dan working tidak disentuh. Tidak mengubah output git status | git reset –soft
membuat working dan staging sama dengan HEAD | git reset –hard
Bekerja paralel menggunakan branch
Branch memungkinkan kita bekerja secara paralel, misalnya ada tim yang menambah fitur, dan ada tim yang melakukan bug fix.
| Keterangan |
Perintah |
| membuat branch baru |
git branch namabranch |
| pindah ke branch tersebut |
git checkout namabranch |
| bikin branch sambil pindah |
git checkout -b namabranch |
| membuat tracking branch untuk branch bugfix di origin |
git checkout –track origin/bugfix |
| membuat tracking branch dengan nama berbeda dengan remote |
git checkout -b myfix origin/bugfix |
| membandingkan branch satu dengan lainnya |
git diff master..fitur-xx |
| membandingkan branch dengan titik awal branch tersebut |
git diff master…fitur-xx |
| menggabungkan branch satu dengan lainnya |
git checkout branch-tujuan |
| |
git merge branch-yang-mau-diambil |
| Mengedit konflik : |
|
| - edit konfliknya |
git add namafile-yang-konflik |
| - remove markernya |
git commit -m “merge fitur-xxx ke master” |
| membatalkan merge yang konflik |
git reset –hard |
Bekerja dengan remote
Interaksi dengan remote repository
| Keterangan |
Perintah |
| mendaftarkan remote repository |
git remote add namaremote url |
| melihat daftar remote repository |
git remote -v |
| menghapus remote repository |
git remote rm namaremote |
| mengambil perubahan di remote |
git remote update |
| mengambil perubahan di satu remote saja |
git remote update namaremote |
| mengambil perubahan di remote, hapus branch di lokal yang sudah tidak ada di remote |
git remote update –prune |
| mengambil perubahan sesuai refspec yang sudah dikonfigurasi |
git fetch namaremote |
| mengambil perubahan kemudian dimerge ke branch lokal yang sesuai |
pull = fetch + merge |
| |
git pull namaremote |
| mengirim perubahan di lokal ke remote |
git push nama-remote nama-branch-lokal:nama-branch-remote |
| mengirim perubahan di lokal ke remote, semua branch yang namanya bersesuaian akan dikirim |
git push nama-remote |
| mengirim perubahan di branch lokal yang sedang aktif ke branch di remote dengan nama yang sama |
git push nama-remote HEAD |
| menghapus branch di remote |
git push nama-remote :nama-branch-remote |
Demikianlah perintah-perintah Git yang kita gunakan sehari-hari. Melengkapi daftar perintah di atas, diagram berikut dapat membantu pemahaman kita tentang konsep dan operasi di Git.
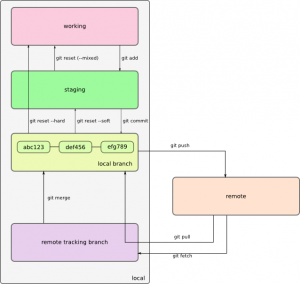
01 Feb 2011
Project Setup dengan menggunakan Gradle dan Git
Hal pertama yang kita lakukan sebelum mulai bekerja tentunya adalah menyiapkan meja kerja dan peralatannya. Sama juga dengan mulai membuat aplikasi. Kita harus menyiapkan struktur folder, library dan framework, dan mengatur semuanya agar siap dikerjakan di meja kita, dalam hal ini IDE.
Di ArtiVisi, biasanya ini dikerjakan oleh programmer senior, yaitu Martinus atau saya sendiri. Kegiatan project setup ini tidak terlalu tinggi frekuensinya, karena biasanya coding project yang existing jauh lebih sering daripada memulai project baru.
Yang jarang dikerjakan biasanya cepat dilupakan. Inilah alasan utama saya menulis posting kali ini, sebagai pengingat buat diri sendiri. Selain itu, mudah-mudahan ada manfaatnya juga untuk para pembaca sekalian.
Sebagai gambaran, tipikal aplikasi di ArtiVisi menggunakan stack standar 2011. Jadi, project setup ini akan dibuat mengikuti stack standar tersebut.
Pertama kali, kita buat dulu projectnya. Satu aplikasi biasanya kita pecah menjadi beberapa komponen, yaitu :
-
Domain Model dan Service API : ini kita pisahkan untuk memudahkan distribusi ke aplikasi client. Perhatikan bahwa yang saya maksud client di sini bukanlah customer pembeli aplikasi, melainkan aplikasi di sisi hilir misalnya user interface yang dibuat dengan Swing. Di sisi client, tidak perlu ada detail implementasi. Cukup class-class domain seperti Produk, Kategori, dsb. Juga kita sediakan service interface, yaitu method yang bisa digunakan untuk menjalankan proses bisnis.
-
Implementasi Service : ini adalah implementasi dari service interface di atas. Implementasi biasanya hanya ada di sisi server. Jadi, jar yang dihasilkan project ini tidak kita distribusikan ke client
-
Konfigurasi : file konfigurasi seperti jdbc.properties, logback-test.xml, smtp.properties, dan setting-setting lain kita juga pisahkan ke project sendiri. Ini tujuannya untuk memudahkan deployment. Seperti kita tahu, biasanya ada beberapa environment seperti development di laptop programmer, testing server, dan production server. Dengan memisahkan konfigurasi, kita bisa menghindari mendeploy konfigurasi development ke server production. Yang perlu diperhatikan di sini, hibernate.cfg.xml dan applicationContext.xml bukanlah file konfigurasi. Itu adalah file aplikasi, walaupun bentuknya xml dan tidak perlu dikompilasi.
-
User Interface : kalau aplikasi desktop, ini hanya satu project saja. Atau mungkin dua dengan konfigurasinya. Tapi untuk web, biasanya kita pecah dua juga. Yang satu berisi source code java, satu lagi berisi aplikasi web. Dengan demikian, bila ada perubahan di controller, kita cukup deploy 1 jar, tidak perlu upload 1 war.
Sebagai ketentuan lain, biasanya nama package selalu kita awali dengan com.artivisi, dan struktur folder mengikuti standar Maven.
Mari kita mulai, berikut rangkaian perintah di linux untuk membuat struktur awal project.
mkdir -p project-contoh/com.artivisi.contoh.{config,domain,service.impl,ui.springmvc,ui.web}/src/{main,test}/{java,resources}
mkdir -p project-contoh/com.artivisi.contoh.ui.web/src/main/webapp/WEB-INF
Outputnya bisa kita lihat sebagai berikut
find .
.
./com.artivisi.contoh.service.impl
./com.artivisi.contoh.service.impl/src
./com.artivisi.contoh.service.impl/src/test
./com.artivisi.contoh.service.impl/src/test/java
./com.artivisi.contoh.service.impl/src/test/resources
./com.artivisi.contoh.service.impl/src/main
./com.artivisi.contoh.service.impl/src/main/java
./com.artivisi.contoh.service.impl/src/main/resources
./com.artivisi.contoh.domain
./com.artivisi.contoh.domain/src
./com.artivisi.contoh.domain/src/test
./com.artivisi.contoh.domain/src/test/java
./com.artivisi.contoh.domain/src/test/resources
./com.artivisi.contoh.domain/src/main
./com.artivisi.contoh.domain/src/main/java
./com.artivisi.contoh.domain/src/main/resources
./com.artivisi.contoh.ui.springmvc
./com.artivisi.contoh.ui.springmvc/src
./com.artivisi.contoh.ui.springmvc/src/test
./com.artivisi.contoh.ui.springmvc/src/test/java
./com.artivisi.contoh.ui.springmvc/src/test/resources
./com.artivisi.contoh.ui.springmvc/src/main
./com.artivisi.contoh.ui.springmvc/src/main/java
./com.artivisi.contoh.ui.springmvc/src/main/resources
./com.artivisi.contoh.config
./com.artivisi.contoh.config/src
./com.artivisi.contoh.config/src/test
./com.artivisi.contoh.config/src/test/java
./com.artivisi.contoh.config/src/test/resources
./com.artivisi.contoh.config/src/main
./com.artivisi.contoh.config/src/main/java
./com.artivisi.contoh.config/src/main/resources
./com.artivisi.contoh.ui.web
./com.artivisi.contoh.ui.web/src
./com.artivisi.contoh.ui.web/src/test
./com.artivisi.contoh.ui.web/src/test/java
./com.artivisi.contoh.ui.web/src/test/resources
./com.artivisi.contoh.ui.web/src/main
./com.artivisi.contoh.ui.web/src/main/java
./com.artivisi.contoh.ui.web/src/main/webapp/WEB-INF
./com.artivisi.contoh.ui.web/src/main/resources
Berikutnya, kita lengkapi dengan dependensi jar. Di ArtiVisi, kita menggunakan Gradle.
Gradle meminta kita untuk mendaftarkan project yang terlibat dalam settings.gradle
include "com.artivisi.contoh.config"
include "com.artivisi.contoh.domain"
include "com.artivisi.contoh.service.impl"
include "com.artivisi.contoh.ui.springmvc"
include "com.artivisi.contoh.ui.web"
Dan ini build file Gradle.
springVersion = "3.0.5.RELEASE"
springSecurityVersion = "3.0.5.RELEASE"
slf4jVersion = "1.6.1"
logbackVersion = "0.9.27"
jodaTimeVersion = "1.6.2"
sourceCompatibility = 1.6
subprojects {
apply plugin: 'java'
apply plugin: 'eclipse'
configurations {
all*.exclude group: "commons-logging", module: "commons-logging"
}
repositories {
mavenCentral()
}
dependencies {
compile "org.slf4j:jcl-over-slf4j:$slf4jVersion",
"org.slf4j:jul-to-slf4j:$slf4jVersion"
runtime "joda-time:joda-time:$jodaTimeVersion"
runtime "ch.qos.logback:logback-classic:$logbackVersion"
testCompile 'junit:junit:4.7'
}
group = 'com.artivisi.contoh'
version = '1.0-SNAPSHOT'
sourceCompatibility = 1.6
task wrapper(type: Wrapper) {
gradleVersion = '0.9.1'
jarFile = 'wrapper/wrapper.jar'
}
}
project('com.artivisi.contoh.domain') {
dependencies {
compile "org.hibernate:hibernate-entitymanager:3.4.0.GA"
compile "org.springframework:spring-tx:$springVersion",
"org.springframework:spring-orm:$springVersion",
"org.springframework:spring-jdbc:$springVersion"
}
}
project('com.artivisi.contoh.service.impl') {
dependencies {
compile project(':com.artivisi.contoh.domain')
compile "org.hibernate:hibernate-entitymanager:3.4.0.GA"
compile "org.springframework:spring-tx:$springVersion",
"org.springframework:spring-orm:$springVersion",
"org.springframework:spring-jdbc:$springVersion"
}
}
project('com.artivisi.contoh.ui.springmvc') {
dependencies {
compile project(':com.artivisi.contoh.service.impl')
compile "org.springframework:spring-webmvc:$springVersion",
"org.springframework:spring-aop:$springVersion"
compile "org.springframework.security:spring-security-web:$springSecurityVersion",
"org.springframework.security:spring-security-config:$springSecurityVersion"
compile "javax.validation:validation-api:1.0.0.GA",
"org.hibernate:hibernate-validator:4.0.2.GA"
}
}
project('com.artivisi.contoh.ui.web') {
apply plugin: 'war'
apply plugin: 'jetty'
dependencies {
compile project(':com.artivisi.contoh.ui.springmvc')
runtime project(':com.artivisi.contoh.config')
runtime "javax.servlet:jstl:1.1.2",
"taglibs:standard:1.1.2",
"opensymphony:sitemesh:2.4.2"
providedCompile "javax.servlet:servlet-api:2.5"
}
}
Build file ini sudah mendeskripsikan semua sub-projectnya. Sebetulnya kita bisa membuat buildfile di masing-masing project, tapi saya lebih suka terpusat seperti ini supaya terlihat keterkaitan antar project.
Karena saya menggunakan Eclipse, saya menambahkan metadata supaya projectnya bisa dibuka di Eclipse. Ini bisa kita lakukan dengan cara menjalankan perintah
dalam masing-masing folder project. Tapi karena terlalu malas, saya gunakan satu baris perintah ini.
for d in */; do cd "$d"; gradle eclipse; cd ..; done
Untung saja pakai linux, jadi bisa coding di command prompt :D
Selanjutnya, kita bisa test dengan melakukan build di project paling hilir, yaitu ui.web
cd com.artivisi.contoh.ui.web
gradle war
Hasilnya ada di folder build/libs
Kita cek apakah semua dependensi sudah terpenuhi dengan perintah berikut.
jar tvf build/libs/com.artivisi.contoh.ui.web-1.0-SNAPSHOT.war
Ini juga bisa langsung dijalankan dengan plugin Jetty yang ada dalam Gradle.
cd com.artivisi.contoh.ui.web
gradle jetty
Outputnya bisa kita lihat di browser, dengan port 8080.
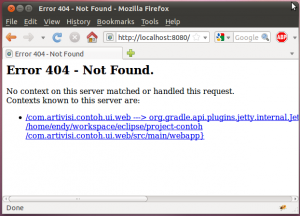
Di situ ada link menuju aplikasi kita. Silahkan diklik.
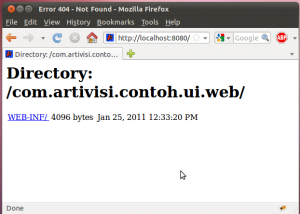
Folder WEB-INF masih terlihat, karena kita belum membuat web.xml. Berikut isi web.xml, masukkan dalam folder com.artivisi.contoh.ui.web/src/main/webapp/WEB-INF
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<!-- Reads request input using UTF-8 encoding -->
<filter>
<filter-name>characterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>characterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<!-- Handles all requests into the application -->
<servlet>
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>
/WEB-INF/springmvc-context.xml
</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Spring MVC Dispatcher Servlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
Sekalian saja kita konfigurasi Spring MVC. Pasang file springmvc-context.xml ini di sebelahnya web.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-3.0.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<!-- Scans the classpath of this application for @Components to deploy as beans -->
<context:component-scan base-package="com.artivisi.contoh.ui.web" />
<!-- Configures the @Controller programming model -->
<mvc:annotation-driven />
<!-- mengganti default servletnya Tomcat dan Jetty -->
<!-- ini diperlukan kalau kita mapping DispatcherServlet ke / -->
<!-- sehingga tetap bisa mengakses folder selain WEB-INF, misalnya img, css, js -->
<mvc:default-servlet-handler/>
<!-- Handles HTTP GET requests for /resources/** by efficiently serving up static resources in the ${webappRoot}/resources/ directory -->
<mvc:resources mapping="/resources/**" location="/resources/" />
<!-- Application Message Bundle -->
<bean id="messageSource" class="org.springframework.context.support.ReloadableResourceBundleMessageSource">
<property name="basename" value="/WEB-INF/messages/messages" />
<property name="cacheSeconds" value="0" />
</bean>
<!-- Resolves view names to protected .jsp resources within the /WEB-INF/views directory -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/templates/jsp/"/>
<property name="suffix" value=".jsp"/>
</bean>
<!-- Forwards requests to the "/" resource to the "hello" view -->
<mvc:view-controller path="/" view-name="hello"/>
</beans>
Kita cek juga apakah projectnya sudah bisa dibuka di Eclipse. Mari kita import.
Pertama, arahkan workspace ke folder project-contoh.
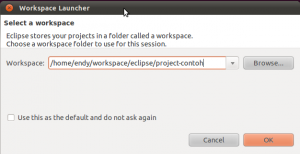
Setelah Eclipse terbuka, kita pilih menu Import Project, untuk membuka 4 project yang tadi sudah kita buat.
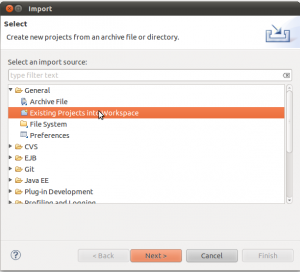
Pilih folder induknya.
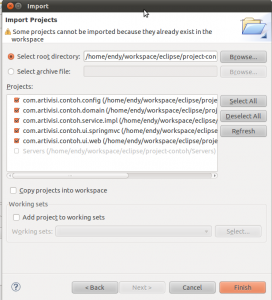
Selesai, semua project kita bisa dibuka. Bahkan kita bisa menjalankan project ui.web dengan cara klik kanan Run in Server. Ini bisa dilihat dari icon project tersebut yang berbentuk bola dunia.
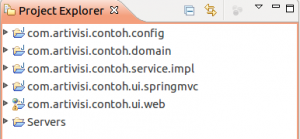
Selesai sudah, mari kita share dengan rekan yang lain.
30 Jan 2011
Di milis JUG, lagi-lagi ada yang tanya tentang load balancing, failover, dan clustering. Jawabannya masih sama sejak 10 tahun saya berkecimpung di urusan coding-mengcoding. Jadi, baiklah saya tulis di blog saja, supaya next time bisa jadi referensi.
Ini sebetulnya dua hal yang berbeda.
Load balancing ya membagi beban.
Failover ya mencegah single point of failure.
Load Balancing
Load balancer terdiri dari satu balancer dan banyak worker.
Bebannya dibagi2 ke semua worker dengan algoritma yang biasanya bisa dipilih.
Bisa merata (round robin) bisa juga dengan bobot (weighted), misalnya worker X mendapat 2 kali worker Y karena dia specnya lebih tinggi.
Atau bisa juga dynamic, artinya si LB akan mengetes kondisi semua worker, mana yang kira2 sedang idle itu yang dikasi.
Mana yang sedang idle ini nanti ada lagi settingnya, apakah melihat CPU usage pakai SNMP, melihat ping response time, whatever.
Failover minimal harus ada 2 titik.
Kalo kita implement LB aja, point of failure (POF) nya adalah si LB.
Begitu LB nya mati, ya udah semua worker gak bisa diakses.
Untuk mencegah ini, LB nya harus ada 2, satu aktif satu standby (pasif).
Contoh aplikasi load balancer :
- HAProxy
- ldirectord (Ultra Monkey)
- Pound
Contoh aplikasi lain yang bisa jadi load balancer :
- Apache (mod_proxy_balancer)
- Nginx
- lighttpd
- bind (DNS Server)
Failover
Contoh aplikasi failover :
Failover artinya mengatasi kalau ada service yang mati. Ada dua jenis aplikasi untuk menangani failover :
- Network Oriented : keepalived, ucarp
- Cluster Oriented : corosync, heartbeat
Penjelasan lengkapnya bisa dibaca di sini. Namun ringkasnya seperti ini:
Network oriented failover memastikan minimal satu service aktif, dan tidak apa-apa bila ada lebih dari satu service yang aktif. Ini cocok untuk dipasang di load balancer, karena load balancer tidak menyimpan state. Tidak masalah kalau user melihat ada dua LB, kadang diarahkan ke LB-1 dan kadang ke LB-2.
Cluster oriented failover memastikan hanya satu service yang aktif, dan tidak apa-apa bila tidak ada service yang aktif. Ini cocok untuk dipasang di database server, karena kita tidak mau database utama dan cadangan dua-duanya aktif. Bisa-bisa datanya tidak tersimpan dengan benar (split brain). Untuk lebih jelas tentang cara kerja cluster-oriented failover, bisa dibaca di sini.
Nah, mudah2an sampe di sini jelas bahwa load balancing dan failover itu dua hal yang tidak saling terkait (orthogonal) dan biasanya dikombinasikan untuk mendapatkan konfigurasi yang robust dan performant.
Setahu saya konsep2x Clustering diatas berlaku pada saat hit pertama.
Pertanyaan saya.. Bagaimana jika request sudah terlayani tetapi ditengah-tengah proses server tiba2x down.. Apakah proses tersebut langsung di alihkan ke server yang lagi up? Jika iya apakah proses akan di restart dari awal atau server yang sedang up bisa melanjutkan sisa dari proses yang belum dikerjakan di server yang telah down?
Sticky Session
Tidak selalu, tergantung konfigurasinya.
Ada konfigurasi sticky session.
Artinya, pada hit pertama, si user akan diberikan penanda, biasanya berbentuk cookie.
Pada hit berikutnya, LB akan melihat cookienya, dan mengarahkan ke server yang sebelumnya sudah mengurus si user ini.
Ada juga konfigurasi non-sticky.
Artinya tiap hit dianggap hit baru, dan didistribusikan ke semua server sesuai algoritma yang dipilih, round robin, weighted, atau dynamic, sesuai penjelasan di atas.
Mau pilih yang mana? Ya tergantung kemampuan LB nya.
Ada yang bisa 2-2 nya sehingga bisa pilih, dan ada juga yang rada stupid sehingga terpaksa pakai non-sticky.
Istilahnya, LBnya layer berapa? Kalo layer 7 biasanya bisa sticky, kalo layer 4 ya gak bisa.
Lebih jauh tentang urusan layer-layeran ini bisa dibaca di sini dan di sini
Nah, apa impact sticky vs non-sticky?
Ini pengaruhnya ke session data.
Session data adalah data sementara masing-masing user.
Karena sifatnya sementara, maka biasanya tidak disimpan secara persistent di tabel database.
Contoh paling klasik adalah isi shopping cart.
Itu barang belum diorder, tapi sudah dipilih, sehingga biasanya belum disimpan di database.
Kalo pake non-sticky, si user pertama milih barang di server X.
Pada saat dia pilih barang kedua, dilayani server Y.
Karena pilihan pertama ada di server X, ya pas dia pilih barang kedua, cuma tercatat 1 barang padahal harusnya 2.
Ini tidak terjadi kalo kita pakai sticky balancer.
Request kedua dan seterusnya akan diarahkan ke server X lagi.
Jadi, sticky atau non-sticky itu impactnya ke temporary data user, sering disebut dengan istilah session data atau user state.
Nah, setelah jelas apa dampaknya sticky vs non-sticky, mari kita lanjut ke pertanyaan selanjutnya.
Kalau untuk Java EE Application Server apakah untuk pertanyaan saya di atas sudah ada featurenya atau perlu ada tambahan produk lagi untuk bisa sharing informasi terhadap state suatu proses yang dijalankan di satu server sehingga jika server tersebut down proses bisa dilanjutkan di server yang lain tanpa merestart proses?
Session Replication
Mengenai urusan session/state management, ini sangat tergantung merek application server yang digunakan.
Secara umum, settingan standar appserver biasanya simpan data session di memori.
Kalau kita enable cluster, misalnya terdiri dari 4 worker, maka data session ini biasanya akan direplikasi ke satu worker lain.
Pada saat worker utama mati, request berikutnya akan diarahkan ke worker cadangannya, sehingga user gak kehilangan data belanjaan.
Biasanya, satu state itu disimpan ke 2 worker saja, bukan direplikasi ke semua untuk alasan efisiensi bandwidth.
Pada penjelasan di atas banyak sekali saya gunakan kata ‘biasanya’. Ini karena kapabilitas dan konfigurasi masing-masing merek appserver sangat berbeda sehingga sulit untuk menggeneralisir kondisinya.
Lalu bagaimana?
Saya biasanya mengambil pendekatan yang universal, yang jalan di semua appserver, sehingga tidak perlu pusing menghafal appserver apa bisa apa settingnya gimana.
Teknik universalnya sederhana: aplikasi webnya dibuat stateless.
Jangan ada simpan data di memori. Simpan semua di database, atau di distributed cache (misalnya memcached).
Di Java, data yang ada di memori antara lain : session variable, static variable, context variable.
Di PHP, CMIIW cuma session dan global variable aja.
Karena selama ini saya menggunakan teknik ini, jadi saya kurang up to date terhadap appserver apa bisa apa settingnya gimana.
Demikian juga tentang load balancer apa support sticky atau tidak, saya tidak pernah memikirkannya.
Pokoknya simpan state di distributed cache atau database, setelah itu mau pakai appserver Tomcat, Jetty, Glassfish, Weblogic, terserah.
Mau pakai load balancer Apache HTTPD, Nginx, lighty, HAProxy, Pound, Ultramonkey, juga terserah.
Demikian sekilas sharing mengenai load balancing dan clustering. Semoga menjadi cerah.
